Agence FinOps & Green IT
Les 7 erreurs à éviter en construisant une architecture serverless
L’architecture serverless est devenue un choix privilégié pour de nombreuses entreprises cherchant à gagner en agilité, réduire leurs coûts d’infrastructure et accélérer leurs cycles de développement.
Pourtant, malgré ses nombreux avantages, elle n’est pas exempte de pièges qui peuvent sérieusement compromettre la performance, la sécurité ou la maintenabilité des applications.
Cet article passe en revue les sept erreurs les plus courantes à éviter lors de la conception d’une architecture serverless, en s’appuyant sur des exemples concrets et des conseils pratiques.
Négliger la conception granulaire des fonctions serverless
L’une des erreurs les plus courantes est de concevoir des fonctions serverless trop larges, cumulant plusieurs responsabilités. Ce manque de découpage nuit à la lisibilité, à la maintenabilité et à la performance. En serverless, chaque fonction doit idéalement remplir un rôle unique, bien délimité, afin de favoriser la clarté du code et de réduire les effets de bord.
Prenons l’exemple d’un système e-commerce. Il est tentant d’implémenter une fonction unique qui reçoit une commande, traite le paiement, envoie une confirmation et déclenche l’expédition. Pourtant, une telle approche génère de la complexité inutile. Il est préférable de découper ce processus en plusieurs fonctions spécialisées, orchestrées par un workflow asynchrone. Cela permet de surveiller plus finement chaque étape, de faciliter les tests unitaires et de redéployer plus facilement en cas de changement localisé.
Une autre conséquence d’un mauvais découpage est l’augmentation du temps de démarrage à froid, un phénomène inhérent au serverless. Plus une fonction embarque de dépendances ou de logique, plus le démarrage est long lorsqu’elle n’a pas été récemment invoquée. Cela peut provoquer des latences pénalisantes pour l’utilisateur final, en particulier sur des applications temps réel.
Sous-estimer les problématiques de gestion d’état
Le paradigme serverless repose sur l’exécution éphémère de fonctions sans serveur permanent. Cette architecture induit souvent l’idée que l’on ne doit pas gérer d’état côté backend. C’est un malentendu. De nombreuses applications nécessitent une forme ou une autre de persistance : suivi d’une session utilisateur, progression d’un processus métier, conservation d’une configuration, ou traitement transactionnel.
Ignorer ces besoins revient à improviser des solutions peu robustes. Par exemple, certains développeurs stockent de l’état temporaire dans des fichiers sur S3 ou dans des messages non persistants. Cela peut fonctionner à petite échelle, mais devient rapidement instable sous charge ou face à des pannes.
Il est essentiel de choisir les bons services de persistance selon la nature des données. Les caches en mémoire comme Redis sont adaptés aux accès fréquents avec des contraintes de latence faibles. Les bases NoSQL comme DynamoDB ou Firestore permettent une forte scalabilité, mais nécessitent une conception rigoureuse des schémas. Les bases relationnelles, quant à elles, restent indispensables pour certaines garanties de consistance transactionnelle.
Négliger la traçabilité et la supervision
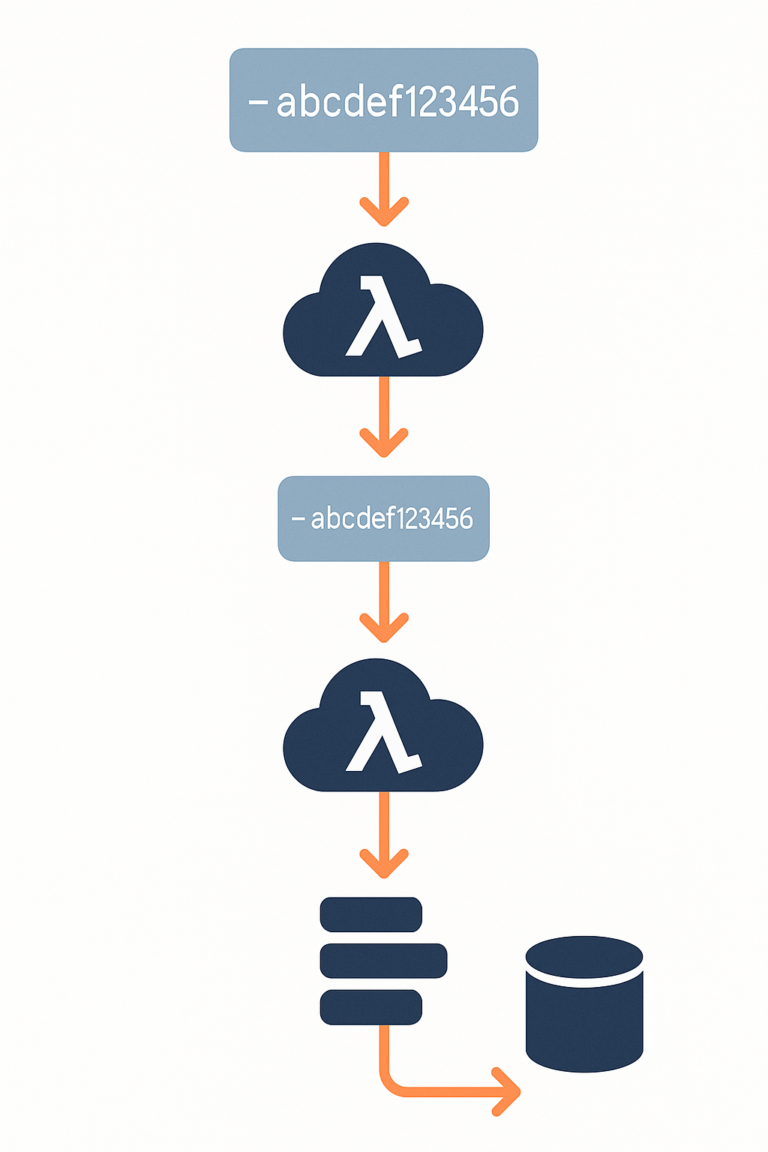
Contrairement à une application monolithique ou à un microservice sur Kubernetes, une architecture serverless disperse la logique dans de nombreuses fonctions exécutées de manière autonome et éphémère. Ce modèle complique considérablement le diagnostic des erreurs et l’analyse des performances si aucune instrumentation sérieuse n’est mise en place.
Beaucoup d’équipes tombent dans le piège de s’appuyer uniquement sur les logs par défaut de la plateforme cloud. Or, ces derniers sont rarement suffisants pour reconstituer le cheminement complet d’une requête ou pour comprendre l’origine d’une défaillance intermittente.
Pour opérer efficacement une architecture serverless, il est indispensable de centraliser les logs, d’ajouter des identifiants de corrélation entre les fonctions, et de mettre en place une solution de traçabilité distribuée. Cela permet de suivre le parcours d’un appel à travers plusieurs fonctions, file d’attente et services tiers. Il devient alors possible de détecter rapidement une anomalie, d’en estimer l’impact, et de la corriger avec précision.
Sous-estimer les coûts et la gestion des quotas
L’un des arguments majeurs du serverless est la maîtrise des coûts grâce à la facturation à l’exécution. Cependant, cet avantage peut vite se transformer en désillusion si l’on ne surveille pas attentivement les usages et les dérives potentielles.
Contrairement aux architectures classiques, le coût du serverless n’est pas prévisible au forfait, mais proportionnel au nombre d’exécutions, à la mémoire consommée, et à la durée d’exécution. Un pic inattendu de trafic, une boucle mal codée ou une dépendance trop gourmande peuvent multiplier les appels et faire grimper la facture de manière exponentielle.
Par ailleurs, chaque fournisseur impose des limites, souvent méconnues : durée maximale d’exécution d’une fonction, nombre d’invocations simultanées, quotas sur les appels à certaines API internes. Une surcharge peut provoquer des erreurs, des rejets d’événements, voire un arrêt de service si ces limites sont atteintes.
Il est donc essentiel de mettre en place des alertes de coût, de comprendre les quotas propres à chaque service, et d’optimiser régulièrement les fonctions pour éviter toute surconsommation.
Ignorer les spécificités de sécurité du serverless
La sécurité est un domaine souvent mal abordé dans les projets serverless, car la disparition des serveurs traditionnels donne un faux sentiment de simplicité. Pourtant, chaque fonction constitue une surface d’attaque potentielle, et chaque intégration avec un service externe doit être rigoureusement sécurisée.
Une erreur classique est d’accorder à une fonction des droits excessifs sur les ressources cloud, par facilité ou méconnaissance. En cas de faille dans le code ou d’appel non contrôlé, ces privilèges peuvent être exploités à grande échelle.
De même, beaucoup d’équipes exposent leurs fonctions via une API Gateway sans authentification robuste, ou avec une validation insuffisante des entrées. Cela ouvre la porte aux injections, aux appels malveillants ou aux fuites de données.
Sécuriser une architecture serverless suppose d’appliquer systématiquement le principe du moindre privilège, de chiffrer toutes les communications, et de mettre en place des mécanismes d’authentification forts, adaptés à chaque point d’entrée.
Supposer que la scalabilité est infinie et instantanée
L’un des attraits du serverless est la promesse de scalabilité automatique. Toutefois, cette scalabilité n’est ni infinie, ni gratuite, ni instantanée. Elle dépend de nombreux facteurs, à commencer par les limites fixées par la plateforme cloud, mais aussi par la capacité de l’écosystème à suivre.
Prenons l’exemple d’un service de traitement d’image basé sur une fonction cloud. Si cette fonction appelle une base de données relationnelle classique pour enregistrer chaque résultat, elle peut facilement saturer le nombre de connexions simultanées à cette base sous forte charge. Le goulot d’étranglement ne vient pas de la fonction elle-même, mais de sa dépendance.
De plus, le serverless introduit une latence d’instanciation (le fameux « cold start »), qui peut se multiplier lors d’un pic soudain de trafic. Une montée en charge mal préparée se traduit alors par une dégradation de performance perceptible.
Pour répondre à ces défis, il est utile de concevoir des architectures tolérantes aux pics, en intégrant des files de messages, des mécanismes de retry, des backoffs exponentiels, voire des circuits-breakers.
Créer une dépendance excessive à un seul fournisseur cloud
Enfin, beaucoup d’architectures serverless sont construites avec une forte dépendance à un fournisseur spécifique : AWS, Google Cloud ou Azure. Cette spécialisation apporte des gains à court terme, mais pose des problèmes à long terme en termes de portabilité, de négociation commerciale ou de conformité réglementaire.
Il n’est pas rare de voir une application intégralement conçue autour de services propriétaires comme AWS Lambda, Step Functions, DynamoDB et S3, rendant toute migration extrêmement complexe. Cette situation de lock-in peut aussi freiner l’adoption de stratégies multi-cloud ou hybrides.
Pour se prémunir, il est judicieux d’introduire dès le départ des couches d’abstraction, de privilégier des formats standards, et d’explorer des alternatives open source comme Knative. Cela permet de garder une certaine agilité stratégique, sans sacrifier les avantages immédiats du cloud.
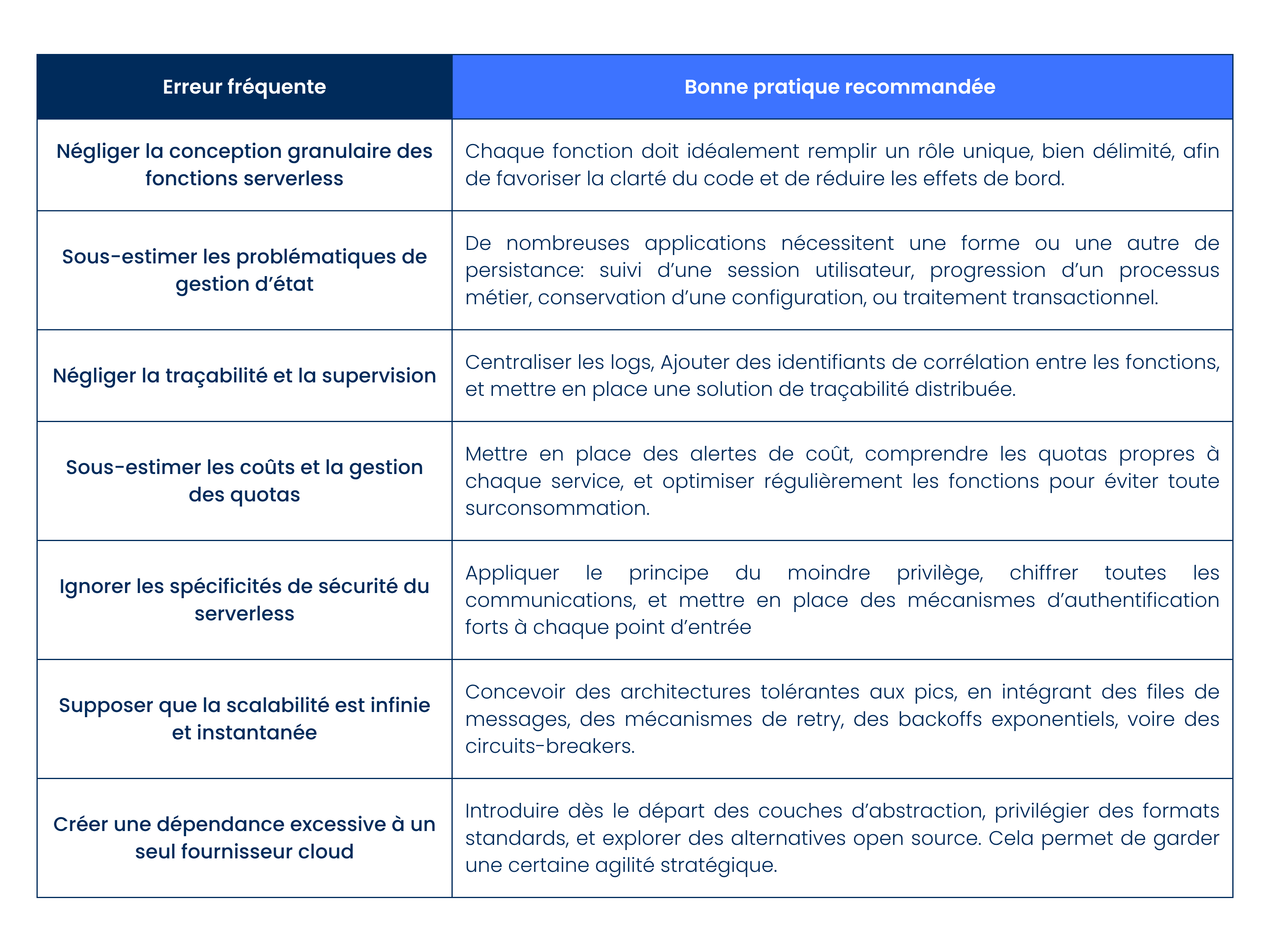
Tableau récapitulatif des 7 erreurs à éviter et des bonnes pratiques associées
Conclusion
Le serverless est un formidable levier pour accélérer les développements, réduire la charge opérationnelle et optimiser les coûts. Mais il vient avec ses propres règles, qu’il faut apprendre à respecter.
En évitant ces sept erreurs fréquentes — mauvaise conception, gestion d’état approximative, absence de supervision, imprévoyance sur les coûts, sécurité négligée, mauvaise gestion de la scalabilité et dépendance excessive à un fournisseur —, il est possible de construire des architectures serverless robustes, durables et réellement efficaces.
Vous concevez ou maintenez une architecture serverless et souhaitez éviter ces écueils dès aujourd’hui ? Parlons-en : notre équipe peut vous aider à auditer, optimiser ou sécuriser votre infrastructure.