Observabilité vs Monitoring : Choisissez la bonne approche à adopter
À mesure que les infrastructures IT évoluent vers des architectures distribuées, Cloud-native et serverless, les interactions entre composants deviennent plus dynamiques et complexes et la complexité s’accroît de manière exponentielle.
La plupart des pannes critiques sont aujourd’hui dûes à des défaillances dans des systèmes interconnectés.
Face à ce défi, les approches classiques de monitoring montrent leurs limites : elles permettent de détecter les symptômes visibles mais peinent à expliquer les mécanismes sous-jacents des dégradations de performance ou des pannes critiques.
La réponse repose sur une approche combinée : le monitoring et l’observabilité.
Dans cet article, nous explorerons leurs différences, leurs complémentarités et leur impact sur la gestion des infrastructures modernes.
Monitoring : Une surveillance et réaction en temps réel
Le monitoring repose sur la collecte continue de métriques standardisées pour suivre l’état de santé d’un système, anticiper les pannes et déclencher des alertes en cas d’anomalies.
Les composants clés du monitoring
Les composants clés du monitoring s’articulent autour de plusieurs éléments complémentaires. Tout commence par la collecte de métriques systèmes et applicatives telles que l’utilisation du CPU, la consommation de mémoire, la latence réseau, le débit en entrée et sortie, le taux d’erreurs, le nombre de requêtes par seconde, le temps de réponse des applications ou encore le taux d’utilisation du disque.
Ces données n’ont de valeur que si elles sont interprétées à travers des seuils d’alerte et des mécanismes de détection d’anomalies. L’idée est de comparer les valeurs observées aux comportements attendus et de générer une alerte en cas d’écart significatif. On peut par exemple déclencher une notification si l’utilisation du CPU dépasse 90 % pendant plus de cinq minutes, ou si le temps de réponse d’une API franchit un seuil critique.
Pour rendre ces informations exploitables, les équipes s’appuient sur des dashboards et du reporting, qui agrègent les données et les présentent sous forme de visualisations dynamiques et de rapports analytiques, offrant ainsi une vision en temps réel de l’état et des performances du système.
Enfin, le monitoring moderne ne se limite pas à observer, mais intègre également l’automatisation des réponses aux incidents. Lorsqu’une alerte survient, des scripts correctifs peuvent être déclenchés automatiquement, qu’il s’agisse de redémarrer un service en surcharge, d’allouer dynamiquement des ressources pour préserver la qualité de service, ou encore de réorienter intelligemment le trafic en cas de saturation d’un serveur backend.
Outils et limites du monitoring
L’écosystème des outils de monitoring est vaste et fragmenté, chaque solution se concentrant sur un domaine spécifique. Les entreprises doivent donc souvent combiner plusieurs outils pour obtenir une vision complète de leur environnement. Certains se spécialisent dans l’infrastructure et le réseau, comme Nagios, Zabbix ou SolarWinds. D’autres sont conçus pour le suivi des conteneurs et de l’orchestration, tels que Prometheus ou le Kubernetes Dashboard. Enfin, des plateformes comme Google Analytics, New Relic ou Datadog offrent des fonctionnalités avancées pour le monitoring des applications et des environnements web.
Si ces outils permettent de détecter rapidement des anomalies en temps réel, ils présentent une limite importante : ils n’expliquent pas les causes profondes des problèmes. Le monitoring se contente de signaler qu’un incident survient, sans fournir d’indications précises sur son origine. Pour dépasser cette limite et comprendre réellement ce qui se passe dans un système complexe, il faut analyser les interactions entre composants. C’est précisément le rôle de l’observabilité, qui complète le monitoring en apportant une vision plus fine et explicative.
Observabilité : Une analyse holistique et proactive des systèmes
L’observabilité repose sur une approche plus large que le monitoring en capturant, corrélant et analysant l’ensemble des signaux générés par un système.
L’observabilité ne se limite pas à la détection d’anomalies ; elle permet de comprendre les interactions complexes entre les composants, d’identifier les goulets d’étranglement et d’anticiper les dégradations de performance avant qu’elles n’impactent la production.
L’observabilité ne se limite pas non plus aux environnements modernes. Les infrastructures on-premise, hybrides et monolithiques peuvent également tirer parti de cette approche pour corréler plus efficacement les événements, améliorer la gestion des ressources et optimiser les performances globales.
Les quatre piliers de l’Observabilité
L’observabilité repose sur l’analyse de plusieurs sources de données, souvent appelées les quatre piliers fondamentaux :
- Métriques : Indicateurs quantifiables reflétant l’état du système en temps réel. Exemples : débit réseau (Mbps), taux d’erreur (%), nombre de requêtes par seconde, latence moyenne d’une API, consommation mémoire.
- Logs : Enregistrements détaillés des événements applicatifs et système, essentiels pour diagnostiquer les erreurs, comportements anormaux et pannes critiques.
- Traces distribuées : Suivi du parcours complet d’une requête à travers différents microservices pour analyser les temps de réponse, les dépendances et les éventuels ralentissements.
- Événements : Actions discrètes qui surviennent dans un système, déclenchant des réponses spécifiques. Exemples : modification de configuration, déploiement d’un nouveau service, basculement d’une instance sur un cluster.
Contrairement au monitoring, qui repose sur des seuils préétablis, l’observabilité permet une analyse exploratoire des comportements inattendus et une corrélation entre les signaux, accélérant ainsi le diagnostic et la remédiation des incidents.
Avantages clés de l’Observabilité
L’observabilité offre une approche bien plus riche que le monitoring classique, en permettant la détection et l’analyse des anomalies en temps réel grâce à l’exploitation des logs et des traces. Ces données fournissent une vision complète et contextualisée des incidents, ce qui limite considérablement les faux positifs générés par des alertes trop basiques.
Elle permet également d’identifier les problèmes de manière proactive, avant même qu’ils ne se traduisent par des interruptions visibles. Par exemple, une hausse progressive de la latence d’un service critique peut être repérée comme un signe avant-coureur de surcharge, offrant ainsi la possibilité d’ajuster les ressources en amont et d’éviter une panne.
Un autre avantage majeur réside dans la réduction du MTTR (Mean Time To Repair). En automatisant l’analyse des causes racines, le temps de diagnostic est considérablement diminué. Les équipes IT peuvent alors passer d’une posture réactive à une stratégie véritablement proactive. Un incident qui aurait nécessité deux heures de recherche manuelle peut être identifié en moins de quinze minutes grâce à une analyse automatisée des logs et aux corrélations établies entre différents services.
Enfin, l’observabilité contribue à l’optimisation des performances et des coûts. En analysant la consommation des ressources en lien direct avec la charge applicative, il devient possible d’ajuster dynamiquement les infrastructures. Cela évite aussi bien le surprovisionnement inutile que les problèmes de sous-performance, garantissant une utilisation plus intelligente et plus durable des ressources disponibles.
Limites actuelles de l’observabilité
L’observabilité, malgré ses nombreux atouts, reste aujourd’hui freinée par plusieurs limites. Son écosystème est encore très fragmenté : aucun outil unique n’offre une couverture complète des besoins, ce qui oblige les entreprises à combiner plusieurs solutions pour collecter, agréger et analyser efficacement les signaux. Cette multiplication des plateformes entraîne non seulement une complexité opérationnelle accrue, mais aussi des coûts de licence et de maintenance importants.
Un autre défi réside dans l’orientation actuelle des outils, qui sont principalement conçus pour des équipes DevOps et SRE déjà expérimentées. Ces solutions privilégient les environnements cloud-native et les cas d’usage liés à l’APM (Application Performance Monitoring), laissant de côté d’autres contextes comme les systèmes hérités (legacy), les environnements hybrides ou encore les infrastructures critiques moins standardisées.
Enfin, l’observabilité génère une quantité massive de données, dont la gestion et l’analyse peuvent rapidement devenir un fardeau. Sans une gouvernance claire et des mécanismes d’intelligence artificielle pour corréler et prioriser les signaux, les équipes risquent d’être noyées sous un flot d’informations brutes, rendant plus difficile la prise de décision rapide. L’un des enjeux majeurs des prochaines années sera donc de simplifier cette complexité, de rendre l’observabilité plus accessible et d’étendre ses capacités à des environnements toujours plus diversifiés.
Quelques outils clés
L’écosystème de l’observabilité s’appuie aujourd’hui sur plusieurs catégories d’outils spécialisés. Les plateformes de logs et de traces, comme l’ELK Stack (Elasticsearch, Logstash, Kibana) ou Splunk, permettent de centraliser et d’analyser de grands volumes de données brutes. Pour la gestion des traces distribuées et l’APM, des solutions comme OpenTelemetry, Jaeger ou AWS X-Ray apportent une visibilité fine sur le comportement des applications. Enfin, des outils de monitoring avancé et de corrélation d’événements tels que Dynatrace, Honeycomb ou Datadog offrent une analyse temps réel et des capacités de visualisation puissantes.
Toutefois, ces solutions ne sont pas exemptes de limites.
Données échantillonnées : pour éviter une surcharge de stockage, certaines plateformes n’enregistrent qu’une partie des métriques et traces, ce qui peut masquer certains signaux critiques.
Corrélation manuelle : même avec des dashboards sophistiqués, les équipes doivent souvent jongler entre plusieurs sources pour remonter à la véritable cause d’un incident.
Coût élevé : la collecte et le traitement massif de logs et de traces engendrent des dépenses importantes en stockage et en puissance de calcul.
En résumé, l’observabilité exige une intégration poussée de données issues de multiples sources. Si elle ouvre la voie à une compréhension fine des systèmes complexes, elle peut rapidement devenir coûteuse et difficile à maintenir sans une gouvernance claire et des mécanismes d’automatisation.
Différences fondamentales entre Monitoring et Observabilité
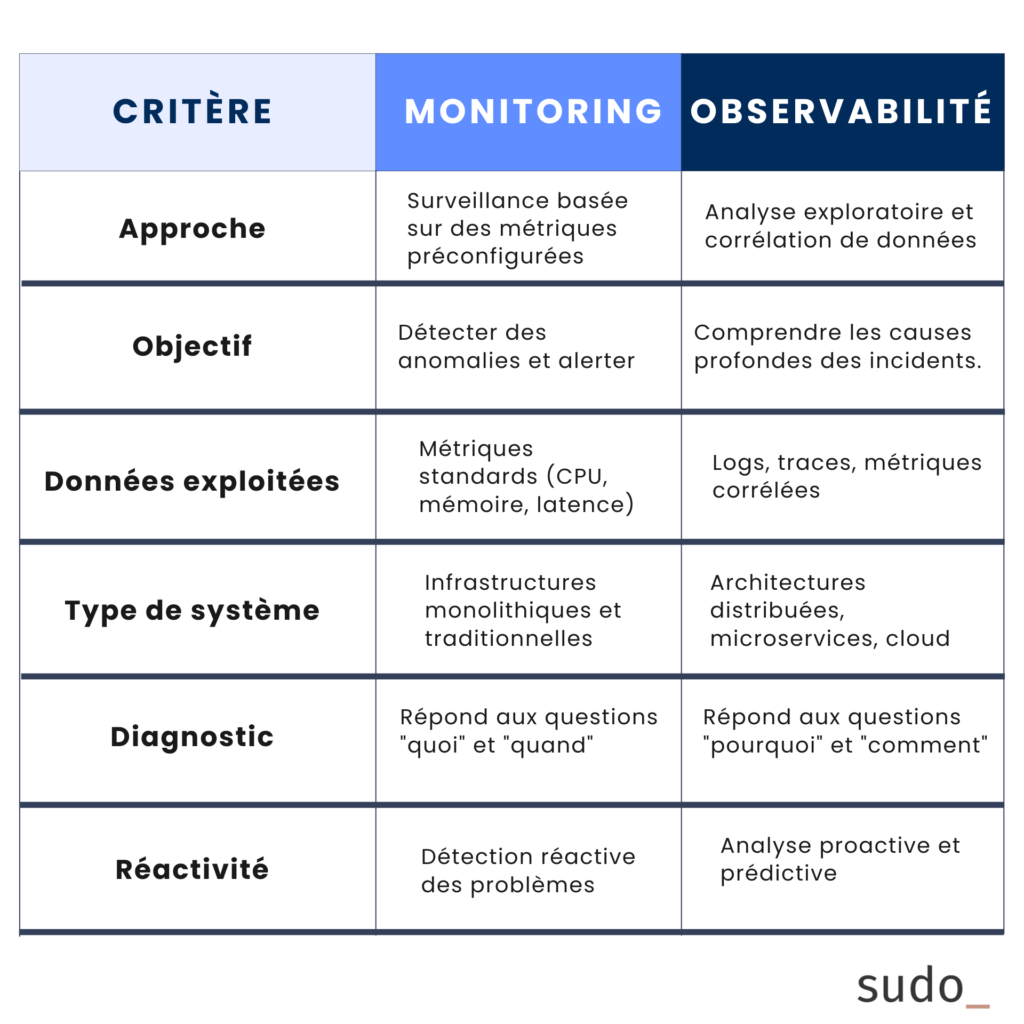
Pourquoi adopter une approche combinée?
Le monitoring et l’observabilité ne sont pas exclusifs, mais complémentaires : le premier fournit une vue macroscopique des performances du système, tandis que le second permet d’analyser en profondeur les interactions et comportements inattendus.
Seul, le monitoring est insuffisant. Seule, l’observabilité est complexe à mettre en œuvre. Ensemble, ils garantissent une supervision efficace et actionnable.
Cas Concrets d’Observabilité
Dans des environnements distribués comme les microservices et le cloud, l’observabilité permet d’identifier rapidement la cause d’une requête qui échoue. En analysant les traces distribuées et en corrélant les logs des différents services, les équipes gagnent une visibilité fine et réduisent considérablement le temps de diagnostic.
Elle joue également un rôle clé dans l’optimisation des performances. Par exemple, un pic de latence peut être directement relié à une surcharge CPU sur un nœud Kubernetes, ce qui ouvre la voie à un ajustement dynamique des ressources et à un meilleur dimensionnement de l’infrastructure.
De plus, les technologies d’intelligence artificielle et de machine learning enrichissent l’observabilité en automatisant les diagnostics. L’analyse en temps réel des logs et des métriques permet de détecter des comportements anormaux, d’anticiper des incidents et, dans certains cas, de proposer des actions correctives automatisées.
Enfin, l’observabilité devient un allié précieux en cybersécurité. En corrélant des logs d’accès, des métriques système et des tentatives de connexion suspectes, elle permet de repérer des activités malveillantes et d’accélérer la réponse aux incidents.
En combinant le monitoring et l’observabilité, les équipes SRE, DevOps et IT Ops peuvent ainsi anticiper les pannes, réduire drastiquement les temps de remédiation et renforcer la résilience globale de leurs systèmes.
Conclusion : Monitoring et Observabilité, un duo incontournable
Le monitoring et l’observabilité ne doivent pas être vus comme deux approches concurrentes mais comme deux facettes complémentaires d’une même stratégie. Le premier fournit une vision d’ensemble, en suivant les métriques clés et en déclenchant des alertes lorsqu’une anomalie survient. La seconde va plus loin, en offrant une analyse détaillée des interactions entre composants, ce qui permet d’identifier plus rapidement les causes profondes et de réduire les temps de remédiation.
L’avenir des infrastructures IT repose sur la maîtrise de cet équilibre. Associer monitoring et observabilité, c’est non seulement anticiper les incidents avant qu’ils n’affectent vos utilisateurs, mais aussi optimiser les performances, mieux contrôler les coûts et bâtir des systèmes résilients capables de s’adapter aux évolutions rapides des environnements cloud et hybrides.
Chez Sudo, nous aidons les entreprises à tirer le meilleur parti de cette complémentarité en alignant supervision technique, performance opérationnelle et optimisation FinOps. Contactez-nous dès aujourd’hui pour échanger sur vos besoins et construire ensemble la stratégie la plus adaptée à votre organisation.